Natural-language processing (NLP) - is an area of computer science and artificial intelligence concerned with interactions between computers and human (natural) languages, particularly how to program computers to fruitfully process large amounts of natural language data.
Sentiment Analysis (SA) - uses natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information.
Background:
I had a project where I was required to use Python/R to do NLP and SA on a collection of user-submitted text data spanning three source websites. The project aimed to gain insights from user data that would enable actionable decisions.
Challenge:
The data collections were huge, and to gain insights, the messy "free-text" data needed to be cleaned to a standard format so they could be processed, broken down into individual components, and analyzed for NLP+SA.
Solution:
Deep Diving in the Data on a Granular Level + Leveraging R's Text Processing Libraries
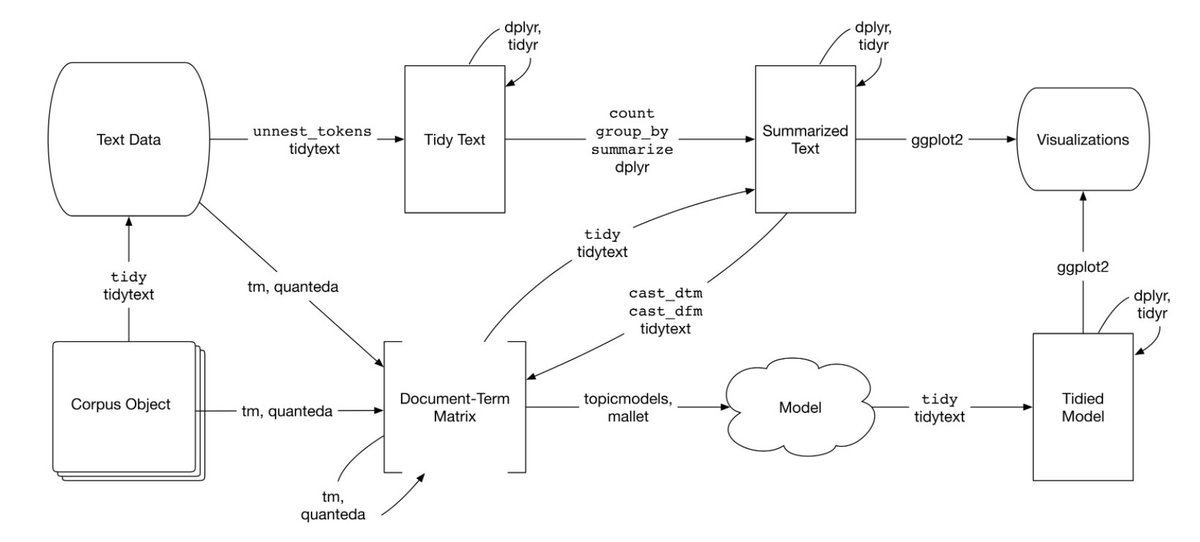
Messy "free-text" data is challenging to coerce into a data frame where each paragraph's sentence is split into parts (e.g., sentences, trigrams, bigrams, and unigrams (words/word pairs)) within various columns while maintaining the ties to its source structure (i.e., which word/word-pairs came from, which sentence and which paragraph).
Accomplishing this task with plain Regular Expressions (Regex) is possible but very tedious to string together a script that captures all the variations in the data. Since R is popular for data mining, many available packages can be leveraged instead of reinventing the wheel with regex.
I created three scripts that enabled me to calculate the information-gain for particular words in relation to a target segment/comparison group, sentiment for user-text data (e.g., sentences, words, word pairs, and the net sentiment of paragraphs), and term frequency-inverse document frequency (tf-idf).
These data points, when presented correctly, can be used in strategic decision-making and enable marketing segmentation of users based on their overall sentiment/polarity, frequency of word/word-pairs use, and other key facets.
Side Note:
Power BI is a great way to present text-analysis data in an interactive dashboard. The drill-down options/filters quickly enable dashboard users with a way to filter data sets by polarity, word/word-pair frequencies, ranges of sentiment, etc.
https://powerbi.microsoft.com/en-us/
Can Python handle NLP as well?
Yes, Python can handle a lot of the everyday NLP tasks, and numerous libraries are available. There is often debate about which language people should use between R and Python, but my opinion is that it depends on the purpose of the analysis. There are various factors to consider, such as developer skill, scalability, and deployment.
For an experienced programmer, R will reduce the total lines of code required to accomplish many everyday text-mining tasks, and the packages available today streamline many of the necessary steps. On the other hand, Python can achieve the same functions with a little more fine-tuning + lines of code. So knowing the scope of the analysis and how the data will be used should guide you in deciding which language to use.
